Loading compiled code
The ugBASIC language provides a command to load binaries.
This is the LOAD command. For example, suppose we have a
program compiled in machine language, which is completely relocatable.
To be able to load it into your ugBASIC program, simply
enter the following command:
executable := LOAD("executable_nop.bin")
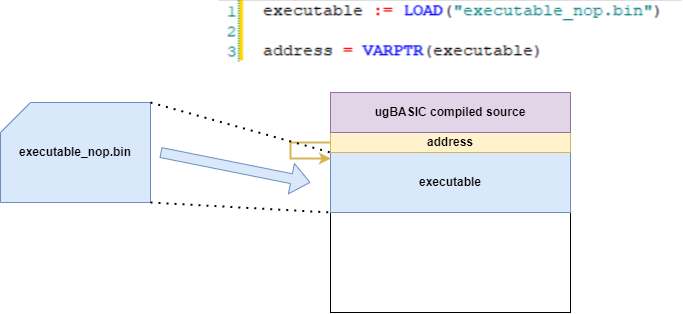
Assuming that the first instruction matches the starting address of the file, it is sufficient to retrieve the address of that variable and use it. To do this you have the command
VARPTR available.
This command returns the address of the given variable:address = VARPTR(executable)Finally, it is necessary to introduce a command that calls the loaded code. The command is the
SYS command (or EXEC, which
will be a synonym). The syntax will be simple:SYS addressNow, insofar as this has significance due to the diversity of the various CPUs, how is it possible to generalize such code? Actually, it is sufficient to copy the binary code in a specific folder, different for each target, and let ugBASIC load the exact version!
Passing parameters and return values
We saw how the SYS (EXEC) command
will allow you to recall a precompiled and relocatable
machine code from outside. For all this to be useful, it is necessary
to give the possibility to communicate with the machine code.
This will be made possible by indicating, at the same time as the
call, the population of specific "input" registers and the recovery of
values from specific "output" registers.
The syntax we will use will be this:
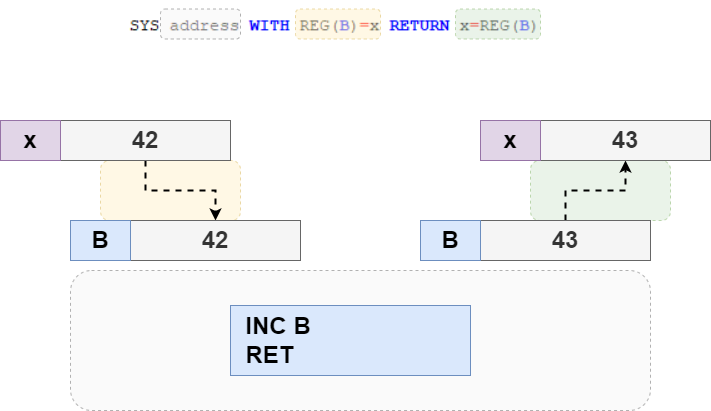
SYS address WITH REG(r1)=v1, REG(r2)=v2, ... RETURN x1=REG(r1), x2=REG(r2), ...
Where r1, r2, ... are the various
processor registers, v1, v2, ... are the values
passed in the various registers and x1, x2, ...
are the variables that will receive the execution result from the various registers.
Since the registers are different from CPU to CPU, it will be necessary to introduce
some tricks to make the code as portable as possible.
First, let's write a small assembly program that increments one of the
registers by one. This is an example for Zilog Z80:
INC B
RET
We assemble it in the executable_increment.bin file obtaining
an executable file that we will load with the previous commands. At this
point, we pass the value to increment with the above syntax.
For example, this program monotonically increments the variable
x
at each keystroke:executable := LOAD("executable_increment.bin")address = VARPTR(executable)x = 0DO SYS address WITH REG(B)=x RETURN x=REG(B) PRINT x WAIT KEYLOOPThe program, as written, works on any computer with a Z80 processor. How to make this program portable to other processors?
Portable assembly code
As we wrote a small assembly program that increments a variable,
and that runs on Zilog Z80 based computers. Let's imagine we want
to do the same thing with the Motorola 6809 processor. What can we do?
First, let's write and assemble a similar program, obviously using
another register:
INCA
RTS
We already suggested moving the compiled executable directly to a
path that has the name of the target. So, for example, if we want
to recompile the example for the TRS-8O Color Computer, it will be
enough to call the program in the same way as the previous one but
put it in the coco subdirectory.
Now let's go back to the source. As written it cannot work because
it uses the wrong registry. How can we differentiate our code to
run on other processors, without writing multiple versions of the
same? Simple: let's use ugBASIC's conditional attribution!
For example, this program increments variables for both the Z80
processor and the 6809 processor.
DIM x AS BYTE
executable := LOAD("executable_increment.bin")
address = VARPTR(executable)
GLOBAL x, address
x = 0
DO
SYS address WITH REG(B)=x RETURN x=REG(B) ON CPUZ80
SYS address WITH REG(A)=x RETURN x=REG(A) ON CPU6809
PRINT x
LOOP
We finish the integration by writing the assembly routine, and the
related function, for the MOS 6502 processor.
INX
RTS
SYS address WITH REG(X)=x RETURN x=REG(X) ON CPU6502
Let's remember to add the call and see how the count appears also
on the Commodore 128, which is indeed equipped with this processor.
Now we come to one of the thorniest problems: what if the code is
not relocatable? Does it need to be loaded to a specific memory
location? For this purpose we use one of the options of the LOAD
command, i.e. the one to indicate in which position to load the code:
executable := LOAD("executable_increment.bin", 49152)
Obviously, VARPTR(executable) will return 49152.
Note that, in this way, it will still be necessary to pay attention to
the space used by ugBASIC, as there are no particular
checks and therefore it is possible that the compiled ugBASIC
collides with the space loaded.
Passing parameters using stack
There is also a different way of passing parameters:
instead of using registers, which are limited in number,
you can use the stack. Which is still a limited resource but
capable of hosting a greater number of parameters.
The syntax for using the stack is simple:
SYS address WITH STACK(ta1)=v1, STACK(ta2)=v2, ... RETURN x1=STACK(tb1), x2=STACK(tb2), ...op1 = 42: op2 = 21SYS address WITH STACK(WORD)=op1, STACK(WORD)=op2 RETURN sum=STACK(WORD)PRINT sumOne important thing: the elements are pushed onto the stack in reverse order of how they appear in the list, so that the caller finds them in the expected order.
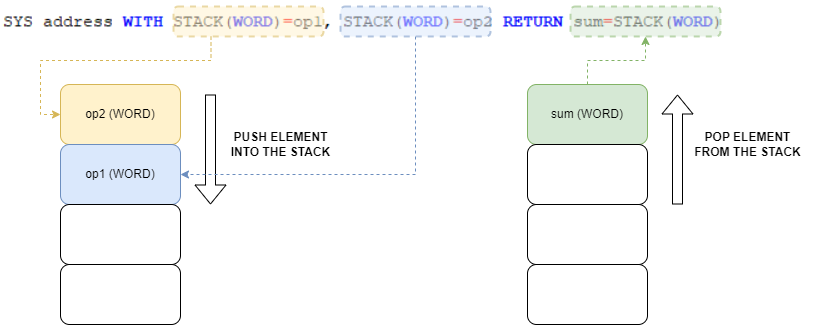
In the specific case, on the stack we will first find the value of
op2
and then the value of op1, but the called program will assign the
value of op1 to the DE register while the value of
the op2 parameter to the HL register.Note that if you use the stack, porting between different processors is easier since all processors have a stack: this is a classic case of isomorphism.
Inline assembly
Inline assembly is definitely a convenience because it allows you to
insert assembly language directly into the ugBASIC source.
Unlike what happens with BASIC source, the assembly language is not
interpreted by the compiler but passed “as is” to the assembler.
This means that it is necessary to know well how both the syntax and
the semantics of these assemblers work, and to have a good understanding
of how the ugBASIC “internals” work.
In this chapter we'll see a really simplified approach to inline assembly,
and in the next ones we'll see how to enable specific additional features.
The simplest way to define an assembly piece is to use the ASM instruction:
ASM LDA #$42
This instruction causes the processor A register to be loaded
with the value 42 hexadecimal, at least on
MOTOROLA 6809 and MOS 6502 processors, while it will generate a syntax
error for the Z80 CPU. How can we avoid the error message? Always
with conditional compilation.
ON CPU6510 ASM LDA #$42
ON CPU6809 ASM LDA #$42
ON CPUZ80 ASM LD A, $42
Obviously it is also possible to write a small piece of code of several
lines: in this case the construct BEGIN ASM ... END ASM
can be used, always prefixed with the indication of the processor
(or even the target) for which it is valid:
DIM x AS BYTE
x = 41
ON CPUZ80 BEGIN ASM
LD A, (_x)
LD B, A
INC B
LD A, B
LD (_x), A
END ASM
ON CPU6502 BEGIN ASM
CLC
LDA _x
ADC #1
STA _x
END ASM
ON CPU6809 BEGIN ASM
LDA _x
INCA
STA _x
END ASM
PRINT x
Importing procedures and functions
We have seen how to call functions in machine language and how to insert
some pieces of assembly into the sources. Now let's move on to the last
aspect of integration: how it delares functions and procedures that can
be called as if they were an integral part of the language.
First, we introduce a mechanism for defining the pattern for calling
a procedure. The simplest syntax is this:
DECLARE PROC name AT address [ON target]
(you can also use PROCEDURE instead of PROC).
For example, suppose you have an assembly routine at address $C000
and it only works under the Commodore 64. You can declare it like this:
DECLARE PROC test AT $C000 ON C64
At this point it will be sufficient to invoke it with one of the
following syntaxes:
CALL test
PROC test
test[]
as if it were any ugBASIC procedure. If desired, parameters
can be added. For each it is obviously necessary to indicate how the value
will be passed to the function written in machine language. The syntax is
like this:
DECLARE PROC name AT address ( p1 [AS t1] ON r1, ... ) [ON target]
Where p1, p2, ... are the parameters,
t1, t2, ... are the (ugBASIC) data types,
and finally r1, r2, ... are the descriptions
of where the values will go.
For example, if we want to create a function that sends data to the serial
port, and the data (as bytes) needs to be pushed onto the stack, we just need
to write the following declaration:
DECLARE PROC serial AT $c000 ( value AS BYTE ON STACK(BYTE) )
We have seen how to import a procedure. Importing a function is just as easy.
The mechanism for defining the pattern for calling an imported function is this:
DECLARE FUNCTION name AT address RETURN rt AS tt [ON targets]
For example, suppose you have an assembly routine at address $C000
and it only works under the Commodore 128, and returns a byte on A
register. You can declare it like this:
DECLARE FUNCTION test AT $C000 RETURN REG(A) AS BYTE ON C128
At this point it will be sufficient to invoke it with one of the following syntax:
x = test[]
Alternatively, you can call it as a procedure and retrieve the parameter later,
with the PARAM command:
CALL test
PROC test
test[]
...
x = PARAM(test)
If desired, you can add parameters. For each it is, of course, necessary to
indicate how the value will be passed to the function written in machine
language. The syntax is like this:
DECLARE FUNCTION name AT address ( p1 [AS t1] ON r1, ... ) RETURN rt AS tt [ON targets]
Where p1, p2, ... are the parameters,
t1, t2, ... are the (ugBASIC)
data types, r1, r2, ... are the descriptions
of where the values will go and rt is the description of where the
result will be stored, as the tt ugBASIC type. For example, if we
want to create a function that sends data to the serial port, and the data
(as a byte) is placed on the stack, and then the function returns the status
of the sending, it is sufficient to write the following declaration in the
A register of the CPU 6502, we will have:
DECLARE PROC serial AT $c000 ( value AS BYTE ON STACK(BYTE) ) RETURN REG(A) AS BYTE ON CPU6502
System functions
The ugBASIC compiler allows you to declare functions
and procedures that are "system" one. What does "system" mean? It
means that the machine code resides in a ROM, preloaded at run time
and therefore already made available to any program that knows how
to call it.
However, since ugBASIC makes available all memory space allowed
by the hardware, it is possible that the ROMs have been disabled
or otherwise made unreachable. Indicating that you want to call
a procedure or a system function, ugBASIC will take
care of re-enabling the ROM before executing the request, deactivating
it on exit.
To declare a procedure or function to be system, simply use the
SYSTEM keyword. For example, this system procedure
on the Commodore 64 scans the keyboard, verifying that a key has
been pressed:
DECLARE SYSTEM PROC scnkey AT $FF9F ON C64
The ugBASIC compiler already has several declarations
of functions or system procedures, declined for the various targets.
They are located in the imports folder on the repository. You can
request their automatic inclusion by using the IMPORT DECLARES command.
Any problem?
If you have found a problem, if you think there is a bug or, more
simply, you would like something to be improved, write a topic on the official forum, or open an issue on GitHub.
Thank you!
